Google Ra Mắt DiffusionGemma: Mô Hình AI Tạo Văn Bản Nhanh Gấp 4 Lần
Mô hình nguồn mở thực nghiệm mới của Google tạo toàn bộ đoạn 256 token song song thay vì từng từ một, đạt tốc độ hơn 1.000 token/giây trên GPU doanh nghiệp.

Google vừa giới thiệu DiffusionGemma, một mô hình ngôn ngữ lớn (LLM) thực nghiệm mang kiến trúc hoàn toàn khác so với các mô hình hiện hành. Thay vì sinh từng token từ trái sang phải như cách các mô hình autoregressive thông thường vẫn làm, DiffusionGemma áp dụng công nghệ khuếch tán (diffusion) để tạo ra toàn bộ một đoạn văn bản cùng lúc. Kết quả là tốc độ suy luận (inference) nhanh hơn tới 4 lần trên GPU chuyên dụng, theo công bố của công ty.
Mô hình được phát hành theo giấy phép Apache 2.0, cho phép sử dụng tự do cho cả mục đích thương mại. Đây là mô hình Mixture of Experts (MoE) với tổng cộng 26 tỷ tham số, nhưng chỉ kích hoạt 3,8 tỷ tham số trong mỗi lần suy luận, giúp giảm đáng kể yêu cầu về bộ nhớ GPU.
Tốc độ vượt trội trên phần cứng phổ thông
Trong điều kiện thực nghiệm, DiffusionGemma đạt hơn 1.000 token/giây trên một GPU NVIDIA H100 và hơn 700 token/giây trên NVIDIA GeForce RTX 5090 – mức tốc độ đáng kể so với các mô hình cùng cỡ dùng kiến trúc truyền thống. Khi chạy bản lượng tử hóa (quantized), mô hình chỉ cần khoảng 18 GB VRAM, phù hợp với các GPU tiêu dùng cao cấp như RTX 4090 hay RTX 5090.
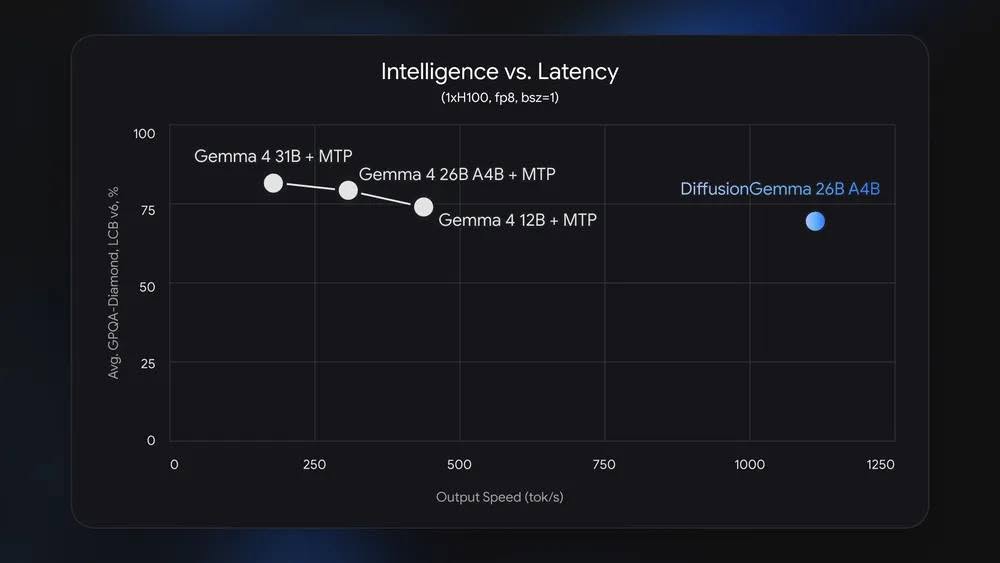
Google lưu ý rằng lợi thế tốc độ này rõ rệt nhất khi chạy cục bộ (local) hoặc ở mức concurrency thấp. Trong môi trường đám mây phục vụ hàng nghìn yêu cầu đồng thời, các mô hình autoregressive vẫn có thể tận dụng phần cứng hiệu quả hơn, khiến ưu thế của DiffusionGemma giảm dần. Ngoài ra, trên các thiết bị dùng kiến trúc unified memory như Apple Silicon Mac, mức tăng tốc có thể không đạt được như trên GPU rời chuyên dụng.
Cơ chế hoạt động: từ nhiễu đến văn bản
Về bản chất, DiffusionGemma hoạt động tương tự cách các mô hình tạo ảnh AI như Stable Diffusion xử lý hình ảnh: bắt đầu từ một tập token ngẫu nhiên, sau đó qua nhiều lượt tinh chỉnh (iterative refinement) để dần hội tụ về đầu ra có nghĩa. Ở mỗi lượt, mô hình khóa những token đã đúng và dùng chúng làm ngữ cảnh để cải thiện phần còn lại, cho đến khi toàn bộ đoạn văn hoàn chỉnh.
Cơ chế này mang lại một đặc tính quan trọng: attention hai chiều. Trong một đoạn 256 token được tạo đồng thời, mỗi token có thể "nhìn thấy" tất cả các token còn lại – không bị giới hạn chỉ nhìn về phía trái như mô hình autoregressive. Đây là lợi thế rõ ràng cho các tác vụ phi tuyến tính như chỉnh sửa nội tuyến, điền code (code infilling), xử lý chuỗi amino acid, hoặc tạo các cấu trúc đồ thị toán học.
Minh chứng thực tế: giải Sudoku
Một trong những ví dụ được Google nêu bật là việc đội ngũ Unsloth đã fine-tune DiffusionGemma để giải bài toán Sudoku – một tác vụ mà các mô hình autoregressive truyền thống vốn gặp khó khăn vì mỗi ô số phụ thuộc vào các ô chưa được điền. Nhờ khả năng xử lý toàn bộ đoạn cùng lúc, DiffusionGemma tiếp cận bài toán này một cách tự nhiên hơn đáng kể.

Hugging Face cũng trình diễn một demo text-to-3D SVG sử dụng mô hình này, tạo đồ họa vector theo từng bước với tốc độ gần thời gian thực – loại tác vụ hưởng lợi trực tiếp từ khả năng sinh văn bản không tuyến tính của DiffusionGemma.
Chất lượng vẫn thấp hơn Gemma 4 tiêu chuẩn
Google thẳng thắn thừa nhận rằng DiffusionGemma hiện vẫn ở trạng thái thực nghiệm và chất lượng đầu ra tổng thể thấp hơn so với Gemma 4 tiêu chuẩn. Lý do là mô hình ưu tiên tốc độ và cơ chế tạo song song, đánh đổi một phần độ chính xác. Với các ứng dụng cần chất lượng cao nhất, Google vẫn khuyến nghị sử dụng dòng Gemma 4 thông thường.
Mô hình hiện có thể tải trên Hugging Face, chạy qua vLLM (với hỗ trợ tích hợp từ Red Hat AI), MLX (dành cho Mac), cũng như trên Google Cloud Model Garden và NVIDIA NIM. Google cũng đang phát triển hỗ trợ native cho llama.cpp, dự kiến ra mắt trong thời gian tới. Bộ công cụ fine-tuning Hackable Diffusion viết bằng JAX cũng được phát hành song song để các nhà nghiên cứu thực nghiệm với kiến trúc mới này.
Bài viết liên quan
19.06.2026, 11:28 am 3
AI Y TẾ CỦA GOOGLE BƯỚC VÀO KỶ NGUYÊN MỚI: TỪ CHẨN ĐOÁN ĐẾN QUẢN LÝ BỆNH LÝ DÀI HẠN

17.06.2026, 10:36 am 7
Lịch Thi Đấu World Cup 2026: Xem Trực Tiếp Ở Đâu Trọn Vẹn Nhất?

06.06.2026, 11:10 am 13
Google Ra Mắt DreamBeans: Ứng Dụng AI Thử Nghiệm Tạo Câu Chuyện Cá Nhân Hóa Hàng Ngày

02.06.2026, 4:47 pm 15
Google dùng Gemini để tự “đạo diễn” sự kiện I/O 2026: Hậu trường đầy sáng tạo từ phim ngắn TPU đến pre-show jellyfish

29.05.2026, 10:46 am 16
Google Công Bố 12 Video Khoảnh Khắc Quan Trọng Từ Keynote I/O 2026: Kỷ Nguyên Agentic AI Đã Đến

26.05.2026, 9:51 am 33
Ứng dụng di động chính thức cho Google Flow và Google Flow Music: Chi tiết đầy đủ từ bản cập nhật tháng 5/2026

25.05.2026, 10:02 am 30